Aug 6 2019
Computer scientists at MIT are hoping to speed up the application of artificial intelligence to enhance medical decision-making, by automating an important step that is normally done manually—and that is turning out to be more difficult as some datasets grow ever-larger.
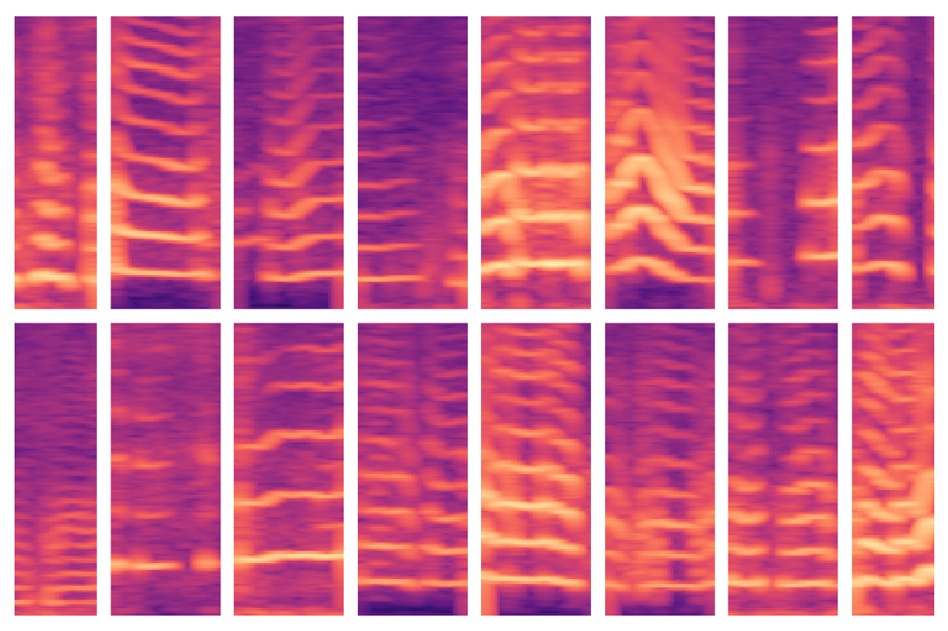 A new MIT-developed model automates a critical step in using AI for medical decision making, where experts usually identify important features in massive patient datasets by hand. The model was able to automatically identify voicing patterns of people with vocal cord nodules (shown here) and, in turn, use those features to predict which people do and don’t have the disorder. (Image credit: MIT)
A new MIT-developed model automates a critical step in using AI for medical decision making, where experts usually identify important features in massive patient datasets by hand. The model was able to automatically identify voicing patterns of people with vocal cord nodules (shown here) and, in turn, use those features to predict which people do and don’t have the disorder. (Image credit: MIT)
The area of predictive analytics shows increasing potential for aiding clinicians to diagnose and treat patients. It is possible to train machine-learning models to detect patterns in patient data to design safer chemotherapy regimens, help in sepsis care, and predict a patient’s risk of dying in the ICU or having breast cancer, to name just a few instances.
Usually, training datasets contain a number of healthy and sick subjects but lack extensive data on each subject. This means, experts have to find just those “features” or aspects in the training datasets that will be critical for making predictions.
However, this “feature engineering” can be a costly and arduous process. It is also becoming much more difficult with the increase in wearable sensors, because scientists can track the biometrics of patients more easily and over extended periods—for instance, tracking voice activity, sleeping patterns, and gait. Following just a week’s worth of monitoring, experts are likely to have many billion data samples for every subject.
Now, MIT researchers are presenting a paper at the Machine Learning for Healthcare conference, describing a unique model that automatically comes to know about features that are predictive of vocal cord disorders.
The features arise from a dataset of around 100 subjects, each with approximately a week’s worth of several billion samples and voice-monitoring data—that is, a small number of subjects as well as a huge amount of data for each subject. The dataset includes signals obtained from a compact accelerometer sensor placed on the necks of the subjects.
In experimental studies, the model employed features that were automatically obtained from these data to categorize patients with and without vocal cord nodules, with excellent precision. These are actually lesions that form in the larynx, mostly due to patterns of voice misuse like yelling or singing songs. Significantly, the model was able to achieve this task without the use of a huge set of manually-labeled data.
It’s becoming increasingly easy to collect long time-series datasets. But you have physicians that need to apply their knowledge to labeling the dataset. We want to remove that manual part for the experts and offload all feature engineering to a machine-learning model.
Jose Javier Gonzalez Ortiz, Study Lead Author and PhD Student, Computer Science and Artificial Intelligence Laboratory, MIT
It is possible to adapt the model to learn patterns of any kind of condition or disease. However, the potential to identify the day-to-day voice-usage patterns related to vocal cord nodules is a critical step in devising better techniques to diagnose, treat, and prevent the disorder, stated the researchers. That may involve developing new methods to detect and alert people to possibly damaging vocal behaviors.
Apart from Gonzalez Ortiz, others who contributed to the paper are John Guttag, the Dugald C. Jackson Professor of Computer Science and Electrical Engineering and head of CSAIL’s Data-Driven Inference Group; Marzyeh Ghassemi, an assistant professor of computer science and medicine at the University of Toronto; and Jarrad Van Stan, Robert Hillman, and Daryush Mehta, all from Massachusetts General Hospital’s Center for Laryngeal Surgery and Voice Rehabilitation.
Forced Feature-Learning
For decades, the MIT team has worked with the Center for Laryngeal Surgery and Voice Rehabilitation to create and examine data from a sensor to monitor the usage of subject voice during all waking hours. The sensor is basically an accelerometer that includes a node fixed to the subjects’ neck and linked to a smartphone. As the subject talks, the smartphone collects data from the displacements occurring in the accelerometer.
In their study, the scientists obtained a week’s worth of this data, known as “time-series” data, from 104 subjects, 50% of whom were found to have vocal cord nodules. There was also a matching control for every patient, that is, a healthy subject of similar six, age, occupation, and various other factors.
Usually, experts are required to manually detect features that might be handy for a model to identify numerous conditions or diseases. Such an approach helps in preventing overfitting—a standard machine-learning issue in health care settings.
That is when, in training, a model “memorizes” subject data rather than learning only the clinically useful features. While testing, those models usually cannot distinguish analogous patterns in earlier unseen subjects.
Instead of learning features that are clinically significant, a model sees patterns and says, ‘This is Sarah, and I know Sarah is healthy, and this is Peter, who has a vocal cord nodule. So, it’s just memorizing patterns of subjects. Then, when it sees data from Andrew, which has a new vocal usage pattern, it can’t figure out if those patterns match a classification.
Jose Javier Gonzalez Ortiz, Study Lead Author and PhD Student, Computer Science and Artificial Intelligence Laboratory, MIT
That time, the main difficulty was averting overfitting and simultaneously automating manual feature engineering. Eventually, the model was forced to learn features without subject data. For the researchers’ task, that meant getting all moments when subjects speak as well as the intensity of their voices.
As it navigates through a subject’s data, the model is programmed to detect voicing segments, which include just about 10% of the data. For every voicing window, the model calculates a spectrogram, a visual depiction of the spectrum of frequencies changing over time, which is usually employed for speech processing tasks. Subsequently, the spectrograms are stored as huge matrices of thousands of values.
However, those matrices are huge and cannot be easily processed. Therefore, an autoencoder—a kind of neural network improved to produce efficient data encodings from massive amounts of data—initially compresses the spectrogram into an encoding of 30 values. Following this, it decompresses that encoding into an individual spectrogram.
Essentially, the model should make sure that the decompressed spectrogram almost looks like the original spectrogram input. In doing so, it is forced to learn the compressed representation of each spectrogram segment input over the whole time-series data of each subject. These compressed representations are the features through which machine-learning models are trained to make predictions.
Mapping Normal and Abnormal Features
During training, the model learns to map those kinds of features to “controls” or “patients.” Compared to controls, patients will have more voicing patterns. When testing on formerly unseen subjects, the model likewise condenses all spectrogram segments into a decreased set of features. its majority then rules—if the subjects have mostly normal voicing segments, they are categorized as controls; if they have mostly abnormal ones, they are categorized as patients.
During experiments, the model performed as precisely as advanced models that need manual feature engineering. Most significantly, the model developed by the researchers performed precisely in both testing and training, implying that it is learning clinically pertinent patterns from the data and not from the subject-specific data.
The scientists are now planning to monitor how different treatments—like vocal therapy and surgery—have an effect on vocal behavior. If the behaviors of patients shift from abnormal to normal over time, it means they are most likely improving. The team is also hoping to utilize a similar method on electrocardiogram data, which is used for monitoring the heart’s muscular functions.