Reviewed by Mila PereraSep 13 2022
An AI model that can handle perception and control simultaneously for an autonomous driving vehicle has been created by a research team that includes Ph.D. student Oskar Natan and his advisor, Professor Jun Miura, of the Active Intelligent System Laboratory (AISL), Department of Computer Science Engineering, Toyohashi University of Technology.
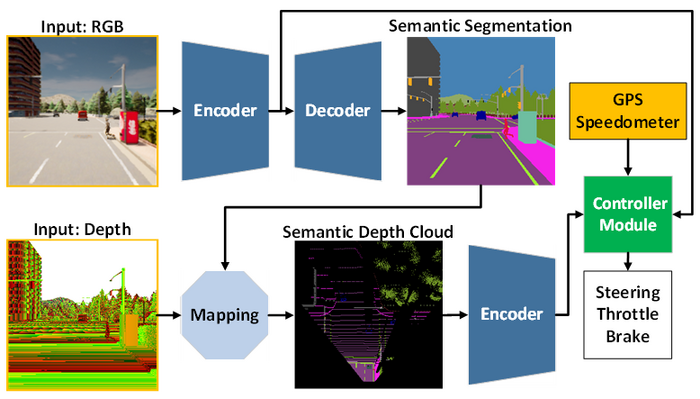 The AI model architecture is composed of the perception module (blue) and the controller module (green). The perception module is responsible for perceiving the environment based on the observation data provided by an RGBD camera. Meanwhile, the controller module is responsible for decoding the extracted information to estimate the degree of steering, throttle, and braking. Image Credit: Toyohashi University of Technology.
The AI model architecture is composed of the perception module (blue) and the controller module (green). The perception module is responsible for perceiving the environment based on the observation data provided by an RGBD camera. Meanwhile, the controller module is responsible for decoding the extracted information to estimate the degree of steering, throttle, and braking. Image Credit: Toyohashi University of Technology.
While operating the vehicle and traveling along a predetermined route, the AI model performs several vision tasks to understand its surroundings. Additionally, the AI model can operate the vehicle securely in a variety of environmental situations and circumstances.
In a typical simulation setting, the AI model gets the best driving ability of some recent models when evaluated under point-to-point navigation tasks.
Details
Multiple subsystems that handle various sensory and control tasks make up the complicated autonomous driving system. Deploying various task-specific modules, however, is expensive and ineffective because numerous configurations are still required to create an integrated modular system.
Additionally, as numerous parameters must be manually modified, the integration procedure can result in information loss. This problem can be solved using quick deep learning research by developing a single AI model with end-to-end and multi-task capabilities.
As a result, the model can provide navigational controls based purely on the observations made by a collection of sensors. The model can now manage the data independently since the manual configuration is no longer required.
The remaining challenge for an end-to-end model is how to derive relevant data so that the controller can accurately estimate the navigational controls. This issue can be resolved by giving the perception module a lot of data so that it can accurately perceive the environment around it.
Furthermore, a sensor fusion technique can improve performance since it combines several sensors to acquire diverse data points. However, the necessity for a larger model to process more data results in an unavoidable high computational load. Moreover, a data preprocessing method is required since various sensors frequently produce data differently.
The model conducts both perceptual and control tasks simultaneously. Thus, the learning imbalance during the training phase could be another problem.
The team suggests an AI model trained with end-to-end and multi-task approaches to address such difficulties. The perception and controller modules comprise the model’s two main structural components. Processing RGB images and depth maps from a single RGBD camera initiates the perception process.
The controller module then decodes the information obtained from the perception module, coupled with the vehicle’s speed measurement and the coordinates of the route point, to calculate the navigational controls.
The team uses a modified gradient normalization (MGN) algorithm to level the learning signal during the training process, ensuring that all tasks can be carried out equally. The team considers imitation learning since it enables the model to learn from a large dataset to match a close-to-human standard.
To reduce the computational load and speed up inference on a device with constrained resources, the team also constructed the model to employ fewer parameters than others.
According to experimental findings in the CARLA, a standard autonomous driving simulator combining RGB images and depth maps to create a general birds-eye-view (BEV) semantic map can improve performance.
The controller module can take advantage of helpful information to accurately predict the navigational controls since the perception module has a better overall view of the environment. According to the scientists, the new model delivers higher drivability with fewer parameters than prior models, making it a better choice for deployment.
Future Outlook
The team is presently modifying and enhancing the model to address several challenges that arise when driving in low-light situations, such as at night or in torrential rain, among others.
The team hypothesizes that adding a sensor, such as LiDAR, that is unaffected by variations in brightness or light will enhance the model’s capability to grasp scenes and lead to improved drivability. The proposed model’s use in actual autonomous driving will be one of the tasks to be completed in the future.
Journal Reference
Natan, O., et al. (2022) End-to-end Autonomous Driving with Semantic Depth Cloud Mapping and Multi-agent. IEEE Transactions on Intelligent Vehicles. doi:10.1109/TIV.2022.3185303.